데이터셋 : https://www.kaggle.com/datasets/rounakbanik/the-movies-dataset
The Movies Dataset
Metadata on over 45,000 movies. 26 million ratings from over 270,000 users.
www.kaggle.com
참고 블로그 : https://lsjsj92.tistory.com/565
파이썬과 함께 추천 시스템(recommendation system) 이해하기 기본편 - content based filtering
포스팅 개요 해당 글에 대한 코드는 아래 github 링크에 전부 올려두었습니다. https://github.com/lsjsj92/recommender_system_with_Python lsjsj92/recommender_system_with_Python recommender system with Python. Contribute to lsjsj92/rec
lsjsj92.tistory.com
1. 데이터 전처리
- 데이터셋 불러오기

-사용할 데이터 뽑기
*평균평점의 불공정을 해결하기 위해 imdb에서 처리한 방법인 weighted rating 사용
관련 이슈: https://www.quora.com/How-does-IMDbs-rating-system-work
How does IMDb's rating system work?
Answer (1 of 23): Thanks for the A2A The formula is given at the bottom of the Top 250 page. The formula for calculating the Top Rated 250 Titles gives a true Bayesian estimate: weighted rating (WR) = (v ÷ (v+m)) × R + (m ÷ (v+m)) × C where: * R = aver
www.quora.com


-콘텐츠 기반 필터링을 위해 비슷한 아이템끼리 추천해주기 위한 장르 컬럼을 list와 dictionary 형태로 바꿈

데이터 전처리 종료
2. 콘텐츠 기반 필터링 추천
-유사도를 계산해야 하기 때문에 문자열을 숫자로 바꾸는 벡터화를 진행해야함

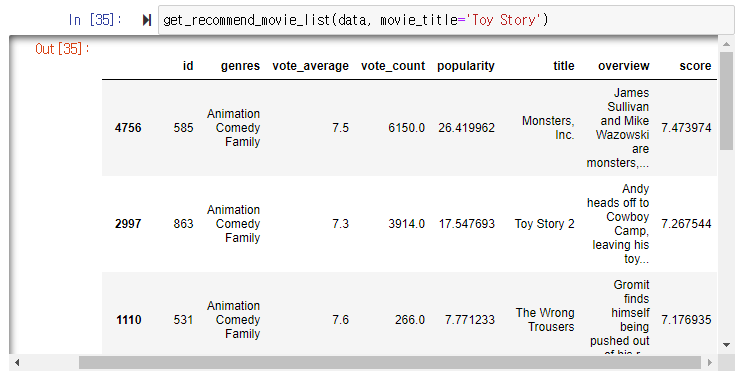
-계산한 유사도를 바탕으로 영화 제목을 넣어주면 그 영화와 비슷한 영화 추천해주는 함수 생성

- Toy Story와 비슷한 장르인 애니메이션, 코미디 장르인 영화를 결과로 보여주는 것을 확인할 수 있음
'추천 시스템 알고리즘' 카테고리의 다른 글
| 할인율 최적화 알고리즘(2) (0) | 2023.09.25 |
|---|---|
| 할인율 최적화 알고리즘(1) (0) | 2023.09.24 |
| 아마존 음식 상품 리뷰 기반 협업 필터링 따라해보기(미완) (0) | 2023.05.16 |
| 협업 필터링 파이썬 실습 (0) | 2023.05.13 |



